Bridging the Gap: Overcoming Cybersecurity Data Annotation Challenges
Explore how data annotation hurdles can impact cybersecurity outcomes (and how to overcome them).

AI isn’t just the future of cybersecurity - it’s the here and now, the present reality shaping our defenses today.
As threats grow more sophisticated by the minute, organizations must adopt AI to detect risks faster, predict vulnerabilities, and respond with precision. Yet there’s a catch: AI’s effectiveness depends entirely on the quality of its training data.
In cybersecurity, where data is inherently messy, fragmented, and sensitive, traditional annotation methods fall short. Generic labeling services lack the contextual awareness and adaptability to meet the industry’s unique demands, leaving critical gaps in threat intelligence.
Understanding the fundamentals of data annotation and labeling is crucial before addressing these cybersecurity-specific challenges.
This is where the real challenge begins. Without accurate, nuanced data annotation, even the most advanced AI models struggle to deliver actionable insights.
Let’s explore how these hurdles impact cybersecurity outcomes and how we can help you address them head-on.
The Hidden Hurdles in Cybersecurity Data Annotation
Data annotation is the cornerstone of an effective AI, yet in cybersecurity, generic labeling services fall dangerously short.
While these tools work for broad use cases, they lack the precision to handle the industry’s unique demands, like volatile threats, fragmented data sources, and stringent compliance requirements. Thus, you end up training a general-purpose LLM to detect zero-day exploits. It may recognize patterns, but without domain-specific context, it misses critical nuances.
The challenges here aren’t just technical, they're existential. Let’s break down the critical hurdles plaguing cybersecurity data annotation today:
1. Data Complexity & the Ever-Changing Threat Landscape
Cybersecurity data, like network traffic and system logs, is inherently unstructured. Unlike standardized datasets, this information sprawls across formats, protocols, and sources, making consistent labeling a daunting challenge. Compounding this is the volatile nature of threats as new attack vectors emerge daily, and adversaries constantly refine tactics (e.g., polymorphic malware that mutates to evade detection, or phishing URLs disguised with dynamic obfuscation).
This is where traditional static labeling approaches falter. Due to this, organizations face a challenge of maintaining accurate and up-to-date datasets, as it requires not just initial annotation, but relentless re-labeling to keep pace.
2. Lack of Ground Truth & Expert Dependency
In threat detection, the absence of definitive ground truth creates a unique annotation challenge. Unlike labeling images or text, where categories are unambiguous, security data often involves interpreting ambiguous signals: Is a network spike a DDoS attack or a benign surge?) Due to this, generic labeling services struggle as resolving such questions demands costly and time-consuming input from domain experts.
While automated methods (like SIEM rule-based tagging) promise scalability, they risk injecting bias—for example, misclassifying novel attack patterns as noise or overfitting to outdated threat signatures. Thus, the result is not satisfactory as the models trained on incomplete labels may have high chances of generating false confidence, masking critical blind spots.
3. Imbalanced Datasets & False Positives
Most cybersecurity datasets are wildly imbalanced: think millions of normal events (like routine logins) versus a handful of actual attacks. This imbalance trains AI models to prioritize "normal" outcomes, effectively teaching them to ignore rare threats.
What's worse is, labeling errors, like marking harmless activity as malicious or missing real attacks, distort the model’s understanding and lead to overlooking real breaches. And for emerging threats like zero-day exploits? There’s simply not enough labeled data to train models effectively, leaving defenses vulnerable to what they’ve never seen before.
In cybersecurity, imbalance isn’t just a data problem, it’s a vulnerability multiplier.
4. Data Privacy & Security Concerns
Handling cybersecurity data is like walking a tightrope. Security logs and threat intelligence often contain IP addresses, credentials, or sensitive PII, data that’s invaluable to defenders but catastrophic if exposed. Compliance like GDPR, HIPAA, and CCPA demands rigorous anonymization before a single label is applied, which strips identifiers without erasing critical threat patterns. But the risks don’t end there.
Storing and processing labeled data requires fortress-like access controls, as one misconfigured permission or unguarded endpoint could turn your defense tool into a leaky sieve. Hence, privacy isn’t just a checkbox; it’s the fragile line between safeguarding your organization and handing attackers the keys.
5. Scalability & Automation Limitations
Data is generated in this domain at an overwhelming scale, think billions of logs, packets, and events daily. Manual annotation can’t keep up, so you rely on automation. But relying solely on automation creates a double-edged sword. This is because, as AI accelerates labeling, it risks propagating errors like misclassifying novel attack patterns as benign that demand costly human correction.
Compounding this, most annotation tools aren’t built for cybersecurity’s nuances. Platforms designed for labeling images or text lack native support for parsing network packet captures, decoding malware binaries, or aligning labels with frameworks like MITRE ATT&CK. The result? Teams waste time making these generic tools work instead of focusing on threat intelligence, which slows model training and leaves gaps in defenses.
6. Evolving Adversarial Tactics
Hackers today aren’t static; they’re shape-shifting. Polymorphic malware alters its code like a digital chameleon, phishing scams evolve from clumsy emails to AI-crafted deepfakes, and zero-day exploits strike before defenses even know they exist. The list is endless. But the problem is that traditional labeled datasets are frozen in time and can’t keep up. So what's the fix?
Weaving real-time threat intelligence, getting fresh insights from MITRE ATT&CK, dark web chatter, or live attack patterns into your labeling process, you can ensure your AI doesn’t just memorize old threats but learns new ones. There is a need for constant refresh so your defenses can withstand these ever-evolving threats.
7. Annotation Tool Limitations for Cybersecurity Data
Most annotation tools feel like trying to fit a square block into a circular hole. Built for images or text, they stumble over cybersecurity-specific formats like PCAP files brimming with network traffic, nested JSON logs, or STIX/TAXII threat feeds. Without native support for these formats, teams waste time modifying workflows or manually parsing data, only to lose critical context in the process.
Complicating this is that the lack of integrations with SIEMs, EDRs, or threat intelligence platforms forces siloed operations, creating bottlenecks in your labeling pipelines.
The Building Blocks of Cybersecurity AI: How Data Annotation Powers Threat Detection
In cybersecurity, AI models are only as robust as the data they’re trained on and how that data is labeled. From phishing emails to malware binaries, every data type demands specialized annotation techniques to extract actionable insights. Below, we break down the critical data types, annotation methods, and real-world applications that form the backbone of effective threat detection:
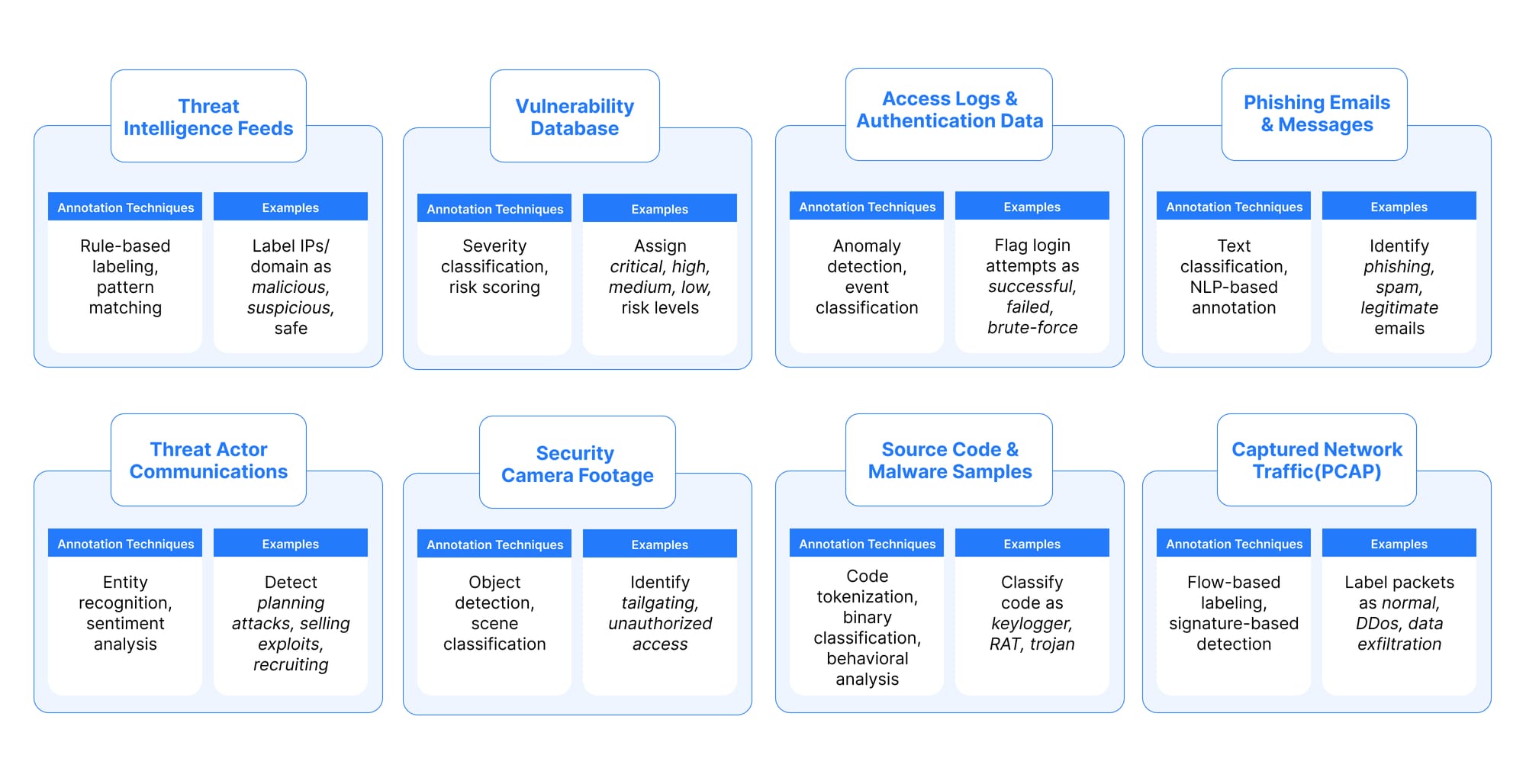
How Metron Transforms Data Annotation for Cybersecurity
At Metron, we address the challenges of data labeling by leveraging a hybrid approach that integrates rule-based methodologies, AI-assisted automation, and expert validation to ensure the highest quality datasets. We believe in having structured automation to handle repetitive tasks, while AI algorithms identify patterns and anomalies.
Crucially, every output undergoes rigorous validation by our cybersecurity experts to ensure accuracy and contextual relevance. To align with industry standards, our context-aware labeling framework incorporates knowledge from MITRE ATT&CK, STIX/TAXII, OCSF, and custom schemas, ensuring datasets reflect real-world threat intelligence and compliance requirements.
For unique organizational needs, our human-in-the-loop (HITL) process enables seamless collaboration: we train machine learning models to flag uncertain samples, allowing your team to focus on reviewing only the most critical edge cases. This way, we prioritize efficiency without compromising precision.
To scale securely, we have developed various purpose-driven tools, one of which is Schema Vault, our proprietary platform for streamlined, consistent data annotation. The result is a tailored solution that will adapt to evolving threats, accelerate model readiness, and transform raw data into actionable insights, empowering organizations like yours to build defenses rooted in accuracy, relevance, and scalability.
The Bottom Line: Better Data, Stronger Defenses
In cybersecurity, AI’s potential is limitless, but only if the data fueling it is precise, relevant, and secure. Generic labeling services can’t navigate the industry’s complexity, leaving models vulnerable to false alarms, outdated patterns, and compliance risks.
We here at Metron can help you bridge this gap. By combining automation with our years of industry expertise, contextual awareness, and custom tooling, we empower organizations to build AI models that detect the right threats at the right time. The outcome? Faster response times, fewer analyst headaches, and a defense posture that evolves as quickly as attackers do.
Connect with Metron to learn how our tailored annotation solutions can turn your raw data into a precision weapon against threats. Let’s build smarter defenses together. Because in cybersecurity, every label counts.








